2.5D Rotoscoping: A Space-Time Topological Approach
Master's thesis at Université Joseph Fourier (Grenoble, France, June 21, 2012)
Abstract
Rotoscoping is the task of reproducing an input video of a 3D scene with a sequence of 2D drawings. It is a common task for creating special visual effects (the drawings are used as masks). It is also a commonly used technique for professional and amateur animators, who use video footage or even recordings of themselves to capture subtle expressions in gestures and movements.
Rotoscoping is a difficult and tedious task, requiring a large number of keyframes to be drawn. One technique that could improve the efficiency of rotoscoping is automatic inbetweening between keyframes. But this has proven to be a very challenging task. The state-of-the-art in automatic inbetweening is limited to keyframes with very little or no change in the topology of the drawings.
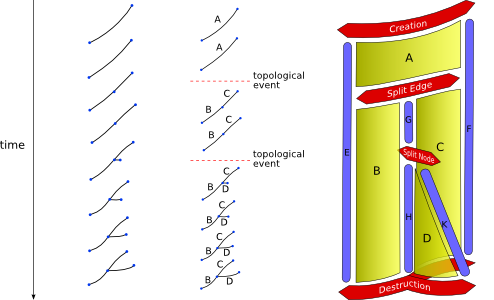
In this thesis, we explore techniques for inbetweening keyframes with different topological structures by building an explicit representation of the space-time topology of the animation. Contrary to recent approaches, which tackle the problem by attempting to reconstuct the depth of the 3D scene (2.5D = 2D + depth), we instead attempt to reconstruct the history of topological events (2.5D = 2D + history).
The report is organized as follows: First, we review the litterature on inbetweening. Then, we present the theory of our representation for space-time topology, as well a some details of its implementation. Then, we present an algorithm using this structure to compute automatically clean vectorial inbetweens from two drawings with inconsistent topologies. Finally, we present some results and discuss future work to improve them.
Paper

Supplemental videos
Comparison between A* and Closest First
A*: didn't find a solution in hundreds of steps
Closest First: finds a solution in 13 steps